Important: In my research so far, nobody seems to have a definite answer for how many unique non-overlapping battleship configurations there truely are...
In this blog post, we explore the process of generating all possible configurations of a Battleship game board using Python. Our goal is to efficiently generate a large number of game boards using parallel processing, while also considering the constraints of memory and storage.
Background
The Battleship game involves placing ships on a grid without overlapping. Each board configuration must include all ships, and the challenge is to generate as many unique configurations as possible. With an estimated 30 billion possible boards, we need an efficient approach to explore this vast solution space.
Project Setup
To tackle this problem, we used Python and its multiprocessing capabilities. Here's a step-by-step guide to our approach:
- Define Ship Configurations: We defined the ships and their sizes, ensuring each ship has a unique identifier.
- Random Ship Placement: We implemented a function to randomly place ships on a grid, ensuring no overlaps.
- Parallel Processing: We used Python's multiprocessing module to divide the task among several processes, each generating a subset of possible boards.
- Progress Tracking: We implemented progress bars to track the number of solutions found in real-time.
- Data Storage: Each valid board configuration was saved immediately in JSON format to ensure progress was recorded.
Python Script
Here is the Python script used for the experiment:
import json
import multiprocessing
import random
from tqdm import tqdm
# Define ship configurations
ships = {
"Carrier": 5,
"Battleship": 4,
"Cruiser": 3,
"Submarine": 3,
"Destroyer": 2
}
def place_ships(grid_size=100):
"""Randomly place ships on a grid ensuring fair use of all cells."""
grid = [""] * grid_size
positions = list(range(grid_size))
for ship, size in ships.items():
placed = False
while not placed:
start = random.choice(positions)
orientation = random.choice(["horizontal", "vertical"])
if orientation == "horizontal" and start % 10 + size <= 10:
if all(grid[start + i] == "" for i in range(size)):
for i in range(size):
grid[start + i] = ship
placed = True
elif orientation == "vertical" and start // 10 + size <= 10:
if all(grid[start + i * 10] == "" for i in range(size)):
for i in range(size):
grid[start + i * 10] = ship
placed = True
return grid
def worker(num_boards, output_queue):
"""Worker function to generate boards."""
for _ in range(num_boards):
board = place_ships()
output_queue.put(board)
def main(total_boards=1000000, num_processes=4):
"""Main function to manage multiprocessing and progress tracking."""
boards_per_process = total_boards // num_processes
output_queue = multiprocessing.Queue()
processes = []
for _ in range(num_processes):
p = multiprocessing.Process(target=worker, args=(boards_per_process, output_queue))
processes.append(p)
p.start()
with open("battleship_boards.json", "w") as f:
for _ in tqdm(range(total_boards), desc="Generating Boards"):
board = output_queue.get()
json.dump(board, f)
f.write("\n")
for p in processes:
p.join()
if __name__ == "__main__":
main()
Data Compression and Sampling
Given the large size of the generated data, we used tarballs to compress the JSON file. This approach significantly reduced the storage requirements, making it easier to handle and transport the data. The compression was achieved using the following command:
tar -czvf battleship_boards.json.tar.gz battleship_boards.json
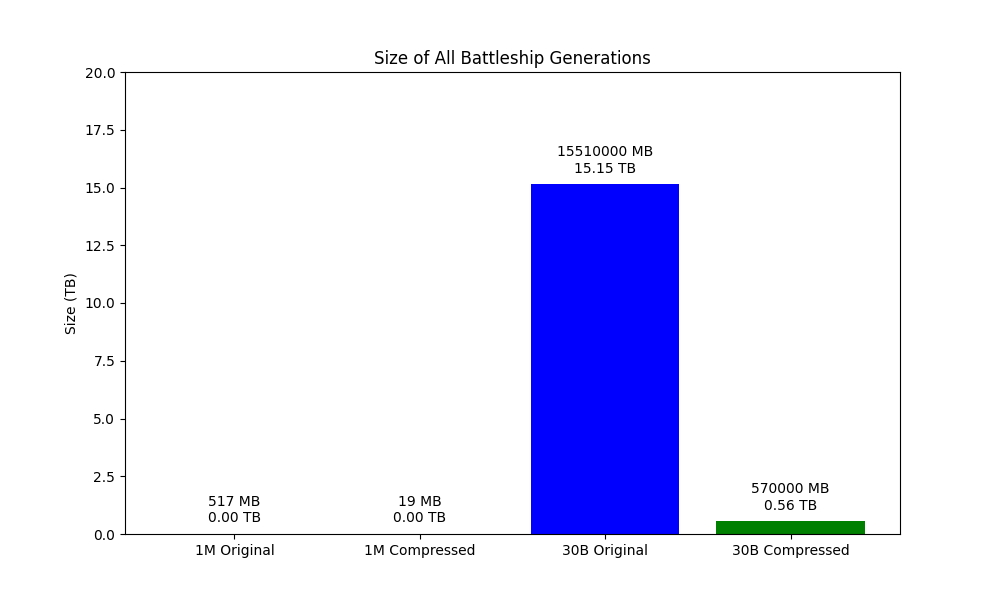
The original file size for 1,000,000 boards was 517 MB, which compressed down to 19 MB. This compression ratio highlights the efficiency of using tarballs for large datasets.
To efficiently sample from the compressed tarball, we developed two bash scripts:
Sample Multiple Boards: This script extracts a specified number of random boards from the tarball.
#!/bin/bash # Variables TARBALL="battleship_boards.json.tar.gz" SAMPLE_FILE="sampled_boards.json" NUM_SAMPLES=1000 # Number of random samples to extract # Stream the tarball and sample lines tar -xzOf "$TARBALL" | shuf -n "$NUM_SAMPLES" > "$SAMPLE_FILE" # Output the location of the sampled file echo "Random samples saved to $SAMPLE_FILE"
Sample One Board: This script extracts a single random board from the tarball and outputs it to standard output.
#!/bin/bash # Variable TARBALL="battleship_boards.json.tar.gz" # Stream the tarball and sample one random line tar -xzOf "$TARBALL" | shuf -n 1
Estimated Dataset Size
The complete dataset for 30,000,000,000 game boards, stored as a JSONL file, is estimated to be approximately 15.51 terabytes. This estimate is based on the size of 1,000,000 boards being 517 MB. The JSONL format is particularly useful for large datasets because it allows for efficient line-by-line processing.
Artifact Description
The JSONL file containing the complete dataset is a valuable artifact for researchers and developers interested in large-scale data analysis or machine learning applications. With sufficient storage space, this dataset can be used to explore various strategies for ship placement, analyze patterns, or train models for game Machine Learning development. The ability to sample from the dataset without full extraction further enhances its utility, allowing users to work with manageable subsets of data.
Results
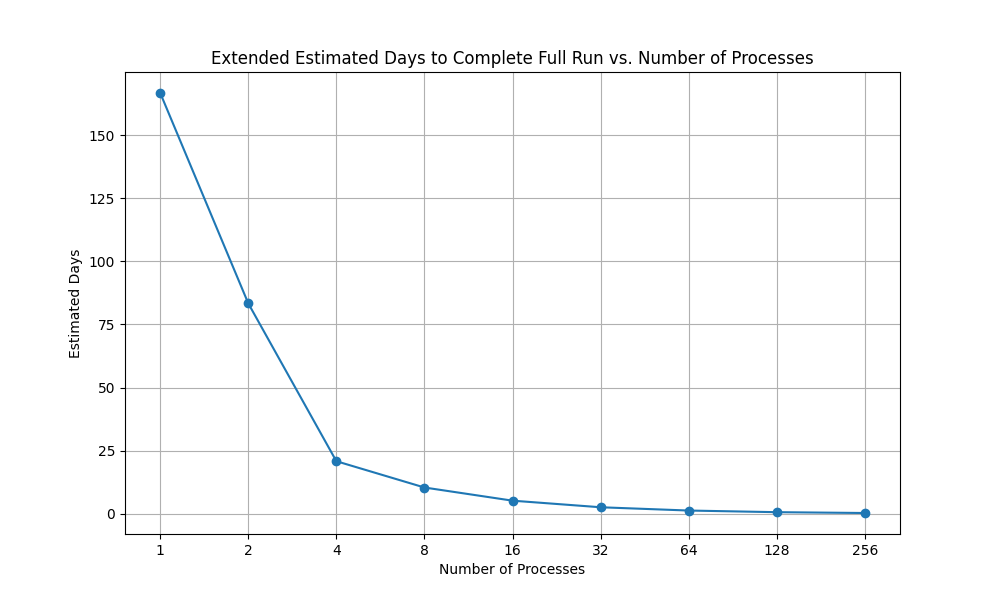
The script successfully generated 1,000,000 boards in about 1 minute on a 4-core i5 from 2012. When considering a move to a 32 hyperthread machine, we estimated a theoretical speedup of 8x, reducing the time to approximately 2.6 days for 30 billion boards.
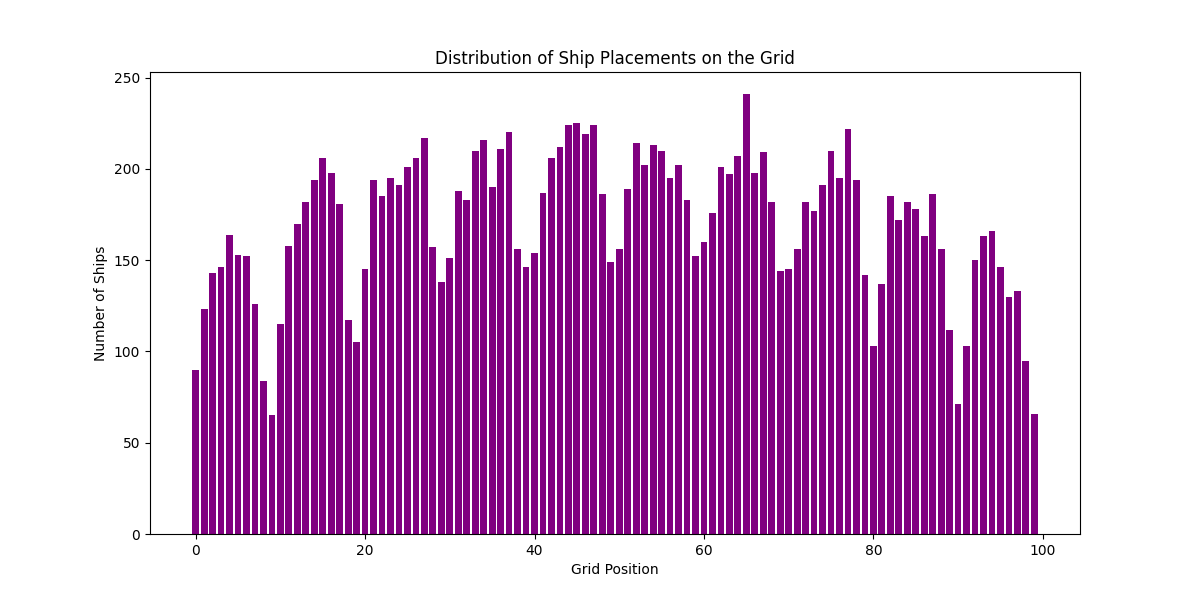
Analysis
- Parallel Processing: Using multiple processes allowed us to efficiently explore the solution space, significantly reducing computation time.
- Progress Tracking: Real-time progress bars provided valuable feedback on the number of solutions found, enhancing the user experience.
- Data Storage: Immediate saving of board configurations ensured that progress was not lost, even in the event of a system failure.
- Compression: We found that compressing the data reduced storage requirements significantly, making it feasible to handle large datasets.
- Sampling: The ability to sample from the compressed tarball without full extraction was crucial for managing large data efficiently.
Conclusion
This experiment demonstrated the power of parallel processing in Python for generating large datasets. By leveraging multiprocessing, we efficiently explored a vast solution space, providing insights into the potential of Python for handling complex computational tasks.
If you're interested in exploring similar problems or optimizing computational tasks, consider using Python's multiprocessing capabilities to maximize performance and efficiency.
This post was inspired by a conversation with an Machine Learning assistant, highlighting the potential of Machine Learning in guiding and enhancing problem-solving processes.
Full conversation here:
See flask-socketio-llm-completions for more Machine Learning tooling!